
반응형
정확한 한 번을 지원하는 방법
- Kafka에서 메시지 보장 옵션은 3가지가 있습니다. 재밌는건 정확한 한 번 옵션 또한 분산 서버 환경에서는 정확한 한 번을 보장하지 못하며 다른 옵션들 또한 아래 사유로 정확한 한 번을 보장하지 못합니다.
- At-least-once semantics - ACK 응답이 안 올경우 한 번도 메시지를 더 발행
- At-most-once semantics - ack 응답이 안와서 retry자체를 안해서 메시지를 발행 안 할 수 있음
- Exactly-once semantics - 오프셋을 다시 읽는 경우
- 정확한 한 번을 지원하기 위해서는 멱등성 프로듀서, 트랜잭션 API, 애플리케이션 레벨에서 중복 제거 총 3가지의 방법이 있습니다.
- 각 방법마다 장단점이 존재하고 현재 프로젝트의 상황에 맞는 방법을 선택해야 합니다.
- 그러면 지금부터 정확한 한 번을 지원할 수 있는 3가지 방법에 대해서 살펴보겠습니다.
1.멱등성 프로듀서 (Idempotent Producer)
- 구현 방법
- enable.idempotence=true 설정
- 프로듀서가 각 메시지에 시퀀스 번호를 부여
- 브로커가 중복된 시퀀스 번호를 감지하여 중복 제거
- 장점
- 구현이 간단함 (설정만으로 가능)
- 성능 오버헤드가 적음
- 트랜잭션 API 방식과 다르게 추가적인 트랜잭션 코디네이터가 불필요
- 리더가 장애가 발생해도 멱등성을 보장함
- 단점
- 리밸런싱 발생시 정확한 한 번 보장을 못함
- 현실적으로 모든 도메인들이 멱등성에 대비해서 API를 작성할 수 없음
- 프로듀서와 브로커 사이의 전송만 보장
- 컨슈머 측면의 중복 처리는 보장하지 않음
2.트랜잭션 API (Transactions)
Exactly-once Semantics is Possible: Here's How Apache Kafka Does it
Exactly-once is a hard problem to solve, but we've done it. Available now in Apache Kafka 0.11, exactly-once semantics.
www.confluent.io
- 구현 방법
- Kafka Stream API OR Kafka Transaction을 사용해서 구현 가능
- transactional.id 설정
- initTransactions(), beginTransaction(), commitTransaction() 사용
- isolation.level=read_committed 설정 (컨슈머)
- 장점
- 프로듀서-컨슈머 전체 구간에서 정확히 한 번 처리 보장
- 별도의 상태 스토어에서 데이터를 관리
- 여러 파티션에 걸친 원자적 쓰기 가능
- 컨슈머-프로듀서 패턴에서 안전한 처리 보장
- 단점
- 성능 오버헤드가 있음 (치명적 단점)
- 트랜잭션 코디네이터가 필요해 추가 리소스 사용
3.애플리케이션 레벨 중복 제거
- 구현 방법
- 메시지에 고유 ID 포함
- 컨슈머에서 처리된 메시지 ID를 저장하고 확인
- 장점
- 비즈니스 로직에 맞춘 유연한 구현 가능
- 외부 시스템과의 연동시 활용 가능
- 단점
- 구현이 어려움
- 추가적인 저장소가 필요할 수 있음
- ex:) DB, S3 …
정리
| 구현 복잡도 | 매우 높음 | 높음 | 매우 높음 |
| 성능 영향 | 미미함 | 중간~높음 | 구현에 따라 다름 |
| 리소스 사용 | 낮음 | 높음 (트랜잭션 코디네이터 필요) | 중간 (별도 저장소 필요할 수 있음) |
| 보장 범위 | 프로듀서-브로커 구간만 | 전체 구간 (프로듀서-컨슈머) | 구현에 따라 다름 |
| 리밸런싱 발생시 정확한 보장 | X | O | 구현에 따라 다름 |
| 유지보수성 | 좋음 | 보통 | 어려움 |
| 외부시스템 연동 | 제한적 | 가능 | 매우 유연함 |
애플리케이션 레벨에서 중복을 제거하는 패턴
- 위에서는 정확한 한 번을 지원하기 위해서 방법들에 대해서 살펴보았습니다. 위와 같은 특정 문제들은 반복적인 패턴을 반복하게되는데, 이러한 문제를 해결하기 위한 패턴들이 발견되기 시작했습니다.
- 이러한 패턴중 크리스 리처드슨이 제안한 마이크로 서비스에서 정확한 한 번을 지원하기 위한 3가지 패턴들을 살펴보겠습니다.
1.Transactional Outbox Pattern
- Transactional Outbox Pattern은 데이터베이스의 트랜잭션과 메시지 발행을 하나의 트랜잭션 내에서 처리하여 메시지 중복이나 유실을 방지하는 패턴입니다.
- 또한, 분산 시스템에서 데이터 변경과 메시지 발행 간의 일관성 문제를 해결하는 데 유용합니다. 일반적으로 이벤트 발행 또는 비동기 마이크로서비스 통신에서 사용됩니다.
패턴의 동작 방식
- Transactional Outbox Pattern의 기본 아이디어는 다음과 같은 두 가지 작업을 하나의 독립된 트랜잭션으로 처리하는 것입니다.
- 비즈니스 데이터 업데이트
- 서비스에서 트랜잭션 내에서 데이터베이스의 비즈니스 데이터를 변경합니다.
- 예를 들어, 주문 생성이나 결제 승인 등의 작업을 수행합니다.
- Outbox 테이블에 이벤트 저장
- 같은 트랜잭션 내에서, 발행할 메시지(이벤트)를 Outbox 테이블이라는 별도의 테이블에 레코드로 저장합니다. 이 이벤트에는 메시지의 본문과 메타데이터가 포함됩니다.
- 비즈니스 데이터 업데이트
- 이렇게 하면 비즈니스 데이터와 Outbox 테이블 업데이트가 하나의 트랜잭션으로 묶여 원자적으로 처리됩니다. 따라서, 트랜잭션이 성공적으로 커밋되면 비즈니스 데이터와 이벤트 메시지가 모두 안전하게 저장됩니다.
Outbox 테이블의 이벤트 발행은 어떻게?
- Outbox 테이블에 저장된 이벤트들은 별도의 이벤트 발행 프로세스(프로듀서)에 의해 Kafka나 RabbitMQ 같은 메시지 브로커로 발행됩니다.
- 이벤트 발행 방식은 다음과 같은 방법들이 있습니다.
- Polling Publisher Pattern
- DB에 저장된 정보를 지속적으로 조회(Pull)하여 목적지로 메시지를 발행하는 방법
- Transaction log tailing Pattern
- DB의 커밋로그를 확인하여 변경된 경우가 있을 경우 브로커에 메시지를 발행 하는 방법
- Outbox 테이블을 Kafka Connect의 CDC(Change Data Capture)와 연계해 자동으로 이벤트를 Kafka에 발행하거나, Debezium 같은 CDC 도구를 사용하여 이벤트 발행을 자동화하는 것도 가능
- Polling Publisher Pattern
Transactional Outbox Pattern 장점
- MSA 환경 운영에 적합
- 각 모듈별 독립된 아웃박스 테이블을 기준으로 이벤트가 발행이 되었는지를 기준으로 서비스의 CS를 관리하면 되므로 운영 관리가 편합니다.
- 데이터 일관성 보장
- 메시지 발행과 비즈니스 데이터 업데이트가 하나의 트랜잭션에 포함되므로, 중간에 실패해도 데이터베이스에 불일치가 발생하지 않습니다.
- 메시지 중복과 유실 방지
- 메시지 브로커로 이벤트가 발행되지 않은 경우 Outbox 테이블에서 재처리할 수 있어 메시지 유실을 방지합니다.
- 오프셋 관리가 불필요
- Kafka의 exactly-once semantics처럼 오프셋 문제를 고민하지 않고도 안정적인 메시지 발행이 가능합니다.
Transactional Outbox Pattern 단점
- Outbox 테이블 관리 오버헤드
- Outbox 테이블에 데이터가 축적되므로, 주기적인 데이터 정리 작업이 필요합니다.
- 복잡성 증가
- Outbox 패턴을 구현하려면 별도의 이벤트 발행 프로세스나 스케줄러가 필요해 시스템이 복잡해질 수 있습니다.
Transactional Outbox Pattern 플로우 예시
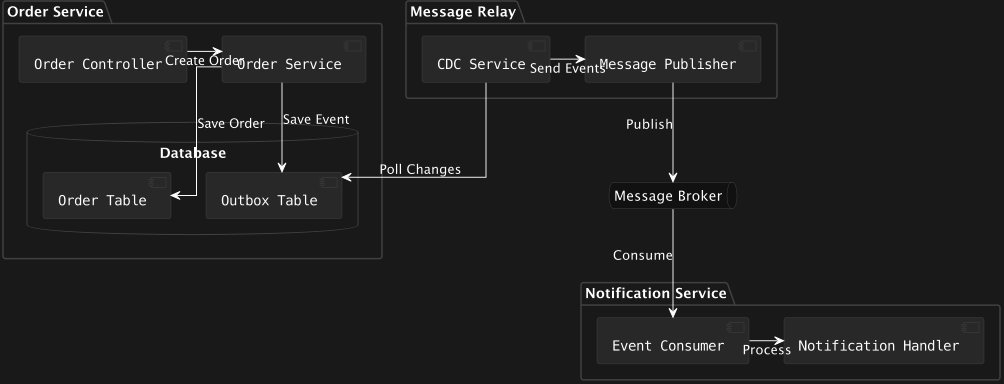
- 주문 MS와 알림 MS가 있는 상황에 Transactional Outbox Pattern에 대한 예시를 설명해보겠습니다.
- 주문 MS에서 주문을 생성하여 Order Service에서 주문을 처리하고 DB에 주문 데이터와, 이벤트를 저장합니다.
- 이때, CDC 서비서는 DB의 변경기록(Write-Ahead-log)을 참고하여 알림MS의 Event에 메시지를 PUB합니다.
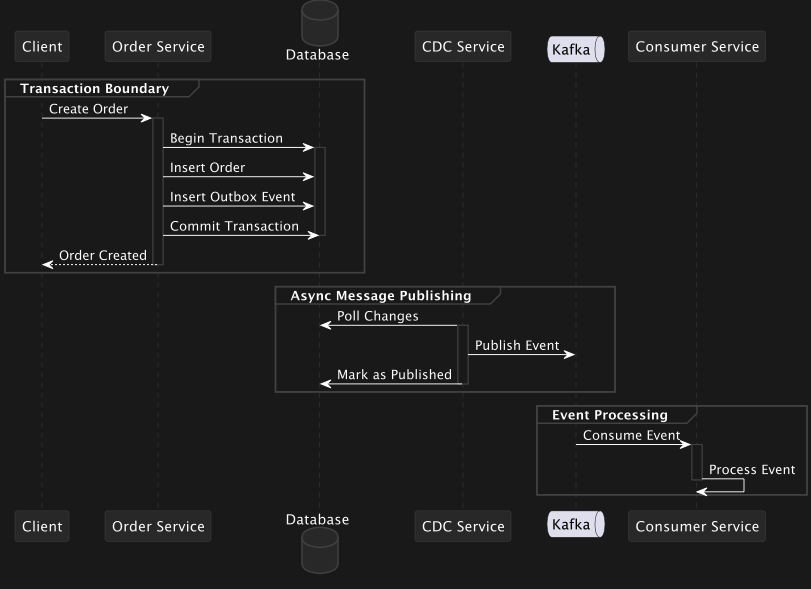
- 위에는 서비스의 플로우를 도식화한 그림입니다. 각 MS의 서비스들은 독립적이 Transaction으로 수행되는것을 확인할 수 있습니다.
- 이를 통해 Cyclic Dependency가 발생하지 않게 되어 MS간의 응집도는 높아지게 되고 결합도는 떨어지게 됩니다. 나아가 정확한 한 번을 유지한 서비스를 구성할 수 있게 됩니다.
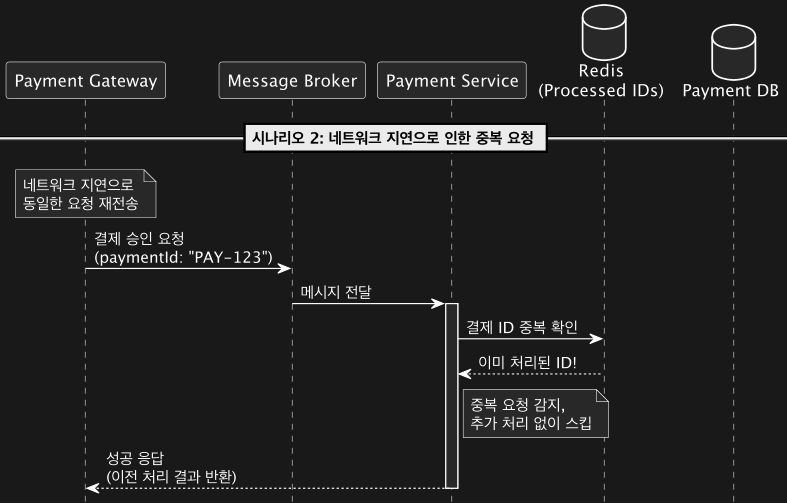
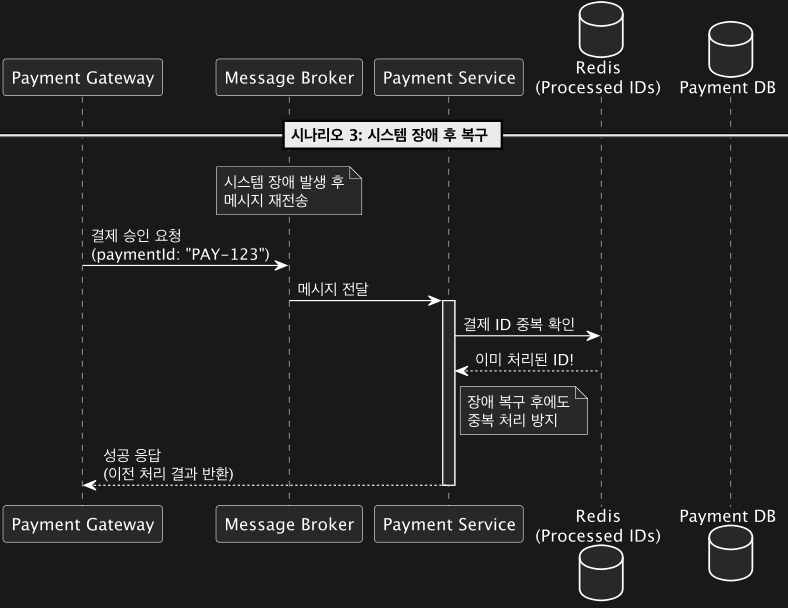
2.Idempotent Consumer Pattern
- Idempotent Consumer Pattern은 같은 메시지가 여러 번 처리되더라도 동일한 결과를 보장하기 위한 패턴입니다.
- 이 패턴은 분산 시스템에서 네트워크 지연, 실패 재시도, 중복 전송 등으로 인해 동일한 메시지가 여러 번 소비자에게 도달할 가능성이 있을 때 유용합니다. 이를 통해 중복 메시지로 인해 정확한 한 번을 유지할 수 있는 애플리케이션 아키텍쳐를 설계할 수 있는 패턴입니다.
패턴의 동작 방식
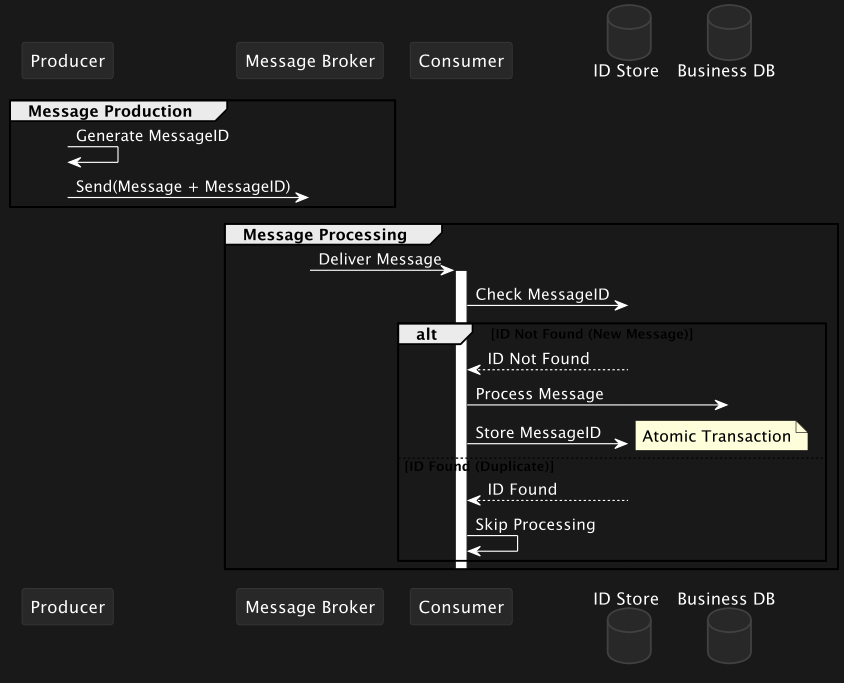
- 중복 메시지 식별
- 메시지를 소비하는 서비스는 각 메시지에 고유한 ID(예: UUID 또는 메시지 ID)를 포함하도록 합니다. 프로듀서가 메시지를 발행할 때 이 고유 ID를 함께 포함하면, 소비자는 ID를 기준으로 메시지 중복 여부를 확인할 수 있습니다.
- 중복 메시지 필터링
- 소비자는 도착한 메시지의 ID를 확인하고, 이전에 처리한 적이 있는 메시지라면 처리를 건너뛰거나 무시합니다. 이 과정은 보통 다음과 같은 방법으로 수행됩니다.
- 중복 메시지 ID를 저장하는 데이터베이스
- 소비자는 메시지를 처리할 때 해당 ID를 데이터베이스에 기록합니다. 이후 동일한 ID의 메시지가 도착하면, DB에서 이를 조회해 중복임을 확인하고 다시 처리하지 않습니다.
- 추가로 캐시 사용을 고민해 볼 수 있습니다. Redis 등과 같은 캐시를 사용하여 최근 처리한 메시지 ID를 일정 시간 동안 저장하고 중복 여부를 확인할 수도 있습니다.
- DB의 멱등 연산 보장 권장
- 메시지가 데이터베이스나 외부 시스템에 업데이트를 수행하는 경우, 해당 연산이 멱등성을 가지도록 설계해야 합니다.
- 예를 들어, 같은 메시지로 여러 번 update 연산을 수행해도 결과가 변하지 않도록 하는 것이 중요합니다.
Idempotent Consumer Pattern 플로우 예시
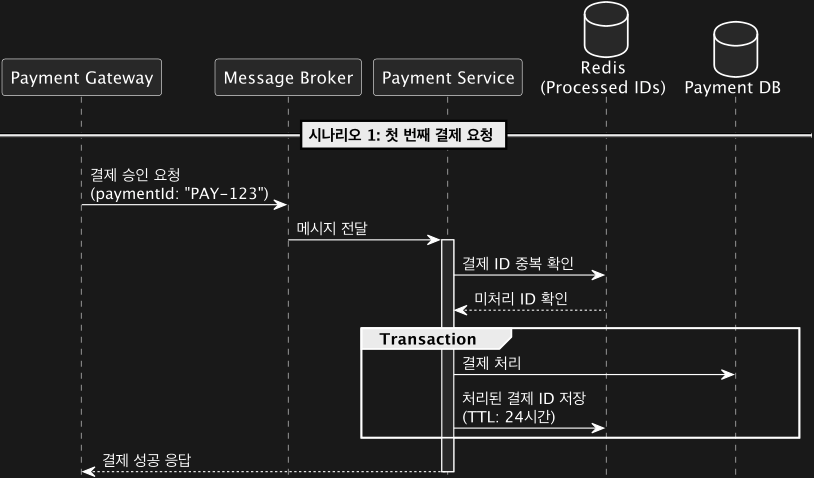
3.State Store Pattern (Kafka Streams 활용)
- State Store Pattern은 Kafka Streams 애플리케이션에서 데이터를 상태 저장소(State Store)에 저장하고 필요할 때마다 접근할 수 있게 하는 패턴입니다.
- 해당 패턴은 스트림 프로세싱에서 상태를 유지해야 할 때 유용하며, 특히 이전 이벤트나 계산된 값을 참조해야 하는 상황에서 사용됩니다.
- Kafka Streams에서는 State Store를 통해 단일 이벤트에 의존하지 않고, 상태를 기반으로 한 복잡한 데이터 처리가 가능합니다.
State Store Pattern의 개념
- State Store
- Kafka Streams에서 사용하는 로컬 저장소로, 키-값 저장소입니다. 이 저장소는 스트림 처리 중에 필요한 상태를 로컬에 유지할 수 있게 해 줍니다. 예를 들어, 애플리케이션이 특정 키의 최신 값을 유지하거나 누적 값을 계산해야 할 때 이 패턴이 사용됩니다.
- Stateful Processing
- Kafka Streams 애플리케이션은 State Store에 저장된 상태를 기반으로 상태 기반 연산을 수행할 수 있습니다. 예를 들어, 현재 누적 합계를 계산하거나 특정 시간 동안의 데이터를 저장하고 업데이트하는 작업이 가능합니다.
- Fault Tolerance (장애 내성)
- State Store는 로컬 디스크에 저장되지만, 체인지 로그(Change Log) 토픽을 통해 Kafka에 비동기적으로 복제됩니다. 이렇게 하면 장애가 발생해도 Kafka에 저장된 변경 이력을 통해 복구할 수 있습니다.
- 지연 업데이트
- State Store는 Kafka Streams 애플리케이션 내에서 실시간으로 읽고 업데이트되며, Kafka 토픽으로부터 데이터를 지속적으로 받으면서 상태를 최신으로 유지할 수 있습니다.
State Store의 구성 요소
- Key-Value Store
- 주로 사용되는 State Store 유형으로, 키-값 형태로 데이터를 저장합니다. 예를 들어, 사용자의 현재 세션 정보나 최신 주문 상태를 저장하는 데 유용합니다.
- Windowed Store
- 시간 창 기반의 데이터를 저장합니다. 예를 들어, 지난 10분 동안 발생한 이벤트의 누적 합계를 저장하는 경우 사용됩니다.
- Session Store
- 사용자 세션을 기반으로 상태를 유지하는 데 사용됩니다. 예를 들어, 사용자가 사이트에 로그인하고 로그아웃할 때까지의 활동을 저장할 수 있습니다.
State Store Pattern 플로우 예시
- 예를 들어, Kafka Streams를 이용해 사용자의 클릭 이벤트를 실시간으로 수집하여 사용자가 웹사이트에서 누적한 클릭 수를 유지하고 싶다고 가정해봅시다.
- State Store 정의
- Kafka Streams 애플리케이션에서 KeyValueStore를 사용하여 각 사용자의 클릭 수를 저장하는 State Store를 정의합니다.
- 클릭 이벤트 처리
- 각 사용자의 클릭 이벤트가 들어오면, 해당 사용자의 ID를 기반으로 State Store에 저장된 이전 클릭 수를 읽어옵니다.
- 상태 업데이트
- State Store에 저장된 클릭 수에 새로 들어온 클릭 이벤트를 더하고, 업데이트된 클릭 수를 다시 State Store에 저장합니다.
- 결과 출력
- 사용자의 클릭 수가 일정 수준에 도달하면, 이를 바탕으로 특정 행동을 수행하거나 Kafka의 다른 토픽에 알림을 발행할 수 있습니다.
- State Store 정의
장점
- 상태 기반 연산 가능
- 단일 이벤트의 정보를 넘어서, 상태를 기반으로 한 복잡한 연산을 수행할 수 있습니다.
- 장애 내성
- Kafka 체인지 로그 토픽을 통해 State Store의 상태를 복제하고 복구할 수 있어 데이터 손실을 방지할 수 있습니다.
- 로컬 캐싱으로 성능 향상
- 로컬에 상태를 저장하여 빠르게 접근할 수 있어 성능이 향상됩니다.
단점
- 메모리 사용 증가
- 상태를 유지하기 위해 메모리와 디스크가 추가적으로 필요합니다.
- 복잡성 증가
- 상태 기반 처리는 단순히 이벤트 기반 처리보다 복잡하며, 관리할 데이터의 크기와 복잡성이 증가할 수 있습니다.
State Store Pattern의 활용 사례
- 실시간 순위 계산
- 사용자 또는 상품의 순위를 실시간으로 계산하여 업데이트하는 경우.
- 세션 상태 관리
- 사용자 활동의 세션을 관리하면서 일정 시간 동안 누적 데이터를 기반으로 행동을 예측하거나 분석할 때.
- 이전 상태 비교
- 실시간으로 들어오는 이벤트와 이전 상태를 비교하여 상태 변경을 추적할 때.
반응형
'Kafka' 카테고리의 다른 글
| 카프카 스키마 레지스트리 (0) | 2023.06.01 |
|---|---|
| 컨슈머의 내부 동작 원리(컨슈머 오프셋, 그룹코디네이터, 스태틱 맴버십,파티션 할당 전략) (0) | 2023.06.01 |
| 프로듀서의 내부 동작 원리(파티셔너, 배치) (0) | 2023.06.01 |
| 카프카의 내부 동작 원리(리플리케이션,리더, 팔로워, 리더에포크, 컨트롤러,로그) (1) | 2023.06.01 |
| 카프카 기본 개념과 구조 (0) | 2023.06.01 |